-
[PR#2] (Quantization) Binarized Neural Networks : Training Neural Networks with Weights and Activations Constrained to +1 or -1 (arXiv 16)Paper Review 2020. 1. 21. 15:41
[20.1.21] draft
[LINK] : https://arxiv.org/abs/1602.02830
Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1
We introduce a method to train Binarized Neural Networks (BNNs) - neural networks with binary weights and activations at run-time. At training-time the binary weights and activations are used for computing the parameters gradients. During the forward pass,
arxiv.org
1. What is BNN?
- BNN은 Quantization의 극단적인 형태로, int8u 또는 float32 등의 자료형이 아닌 1bit로 이루어진 Binary 정보만을 이용해 연산하는 Network이다.
- MNIST BNN 환경에서 GPU kernel의 Binary 연산에 대한 Optimization을 통해 Binary matrix multiplication이 7배 빨라질 수 있음을 보였다.(중요한 점은 Operation 단위까지의 수정이 필수적이라는 것이다.).
- Memory Size는 32x 줄었고, Memory Access time도 32x 줄었다.
- Dropout과 비슷한 Regularization 효과를 가지고 있음을 주장하고 있다.
- Binarizaiton에는 Deterministic과 Stochastic한 방법이 있다.
1. Deterministic Binarization

2. Stochasitc Binarization

Stochasitc Binarization에서는 Random bits을 생성해야하기 때문에 복잡한 Hardware 구현이 필요하므로, 본 논문에서는 Deterministic Binarization을 사용했다.
2. BNN's Activation
- BNN의 Activation은 아래와 같이 일어난다.
- Forward Activation의 경우 양수이면 1, 음수이면 -1로 Activate한다. 하지만 Backpropagation에서 Sign 함수의 미분형태를 생각해보면, Backpropagation할 때 항상 기울기 0이 곱해져 Weight의 Update가 일어나지 않는다.

- 따라서 이를 방지하기 위해 Backpropagation 시에는 STE(Straight-Through Estimator, htanh의 미분형)를 이용해 -1< x < 1 인 값에 대해서만 BackPropagation이 일어나게 한다. 이를 Saturation으로도 볼 수 있는데, 절대값이 1보다 커지면 기울기가 0이 되어 Weight Update가 일어나지 않게 되기 때문이다.
- 또한 여기서 BackPropagation은 Binarized되지 않고 Real Value로 일어난다는 것을 알 수 있다.

(AI Robotics KR 자료 참조 : Figure from Darabi, Sajad, et al. "BNN+: Improved binary network training." arXiv preprint arXiv:1812.11800 (2018))
3. BNN's Algorithm
A. Overall Structure
1) Weight와 Activation이 XNOR을 통해 Multiply된다.
2) Real Valued Weight를 Update항상 -1, 1 사이로 유지


B. Shift based Batch Normalization
- Batch Norm 시에 Sign bit만 원하기 때문에 Scale을 할 필요 없이 Shift만 하면 된다. 따라서 Batch Norm의 결과를 Float로 낼 필요 없이 intVal로 내어도 된다.
C. Adam to Shift based AdaMax

D. First Layer
- First Layer의 input은 Binary Data가 아닌, 일반적인 Image Data이므로, 이는 다른 방법으로 처리해주어야 한다.


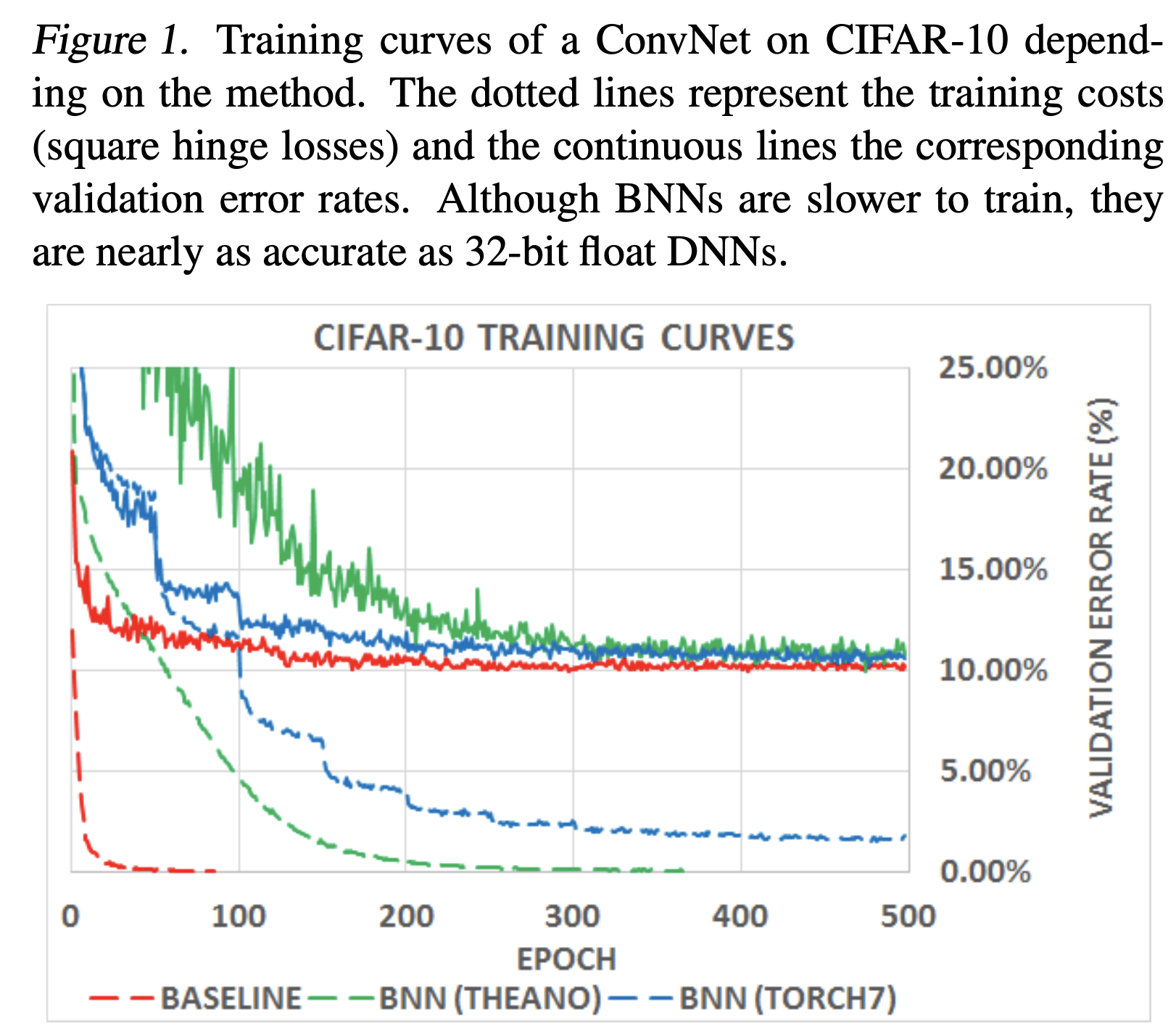
4. Result
CIFAR-10으로 결과를 보면 Acc 손실이 적은 편인 것을 확인할 수 있다.

'Paper Review' 카테고리의 다른 글
ALBERT(ICLR2020) 리뷰 (0) 2020.07.09 Effective Approaches to Attention-based Neural Machine Translation 리뷰 (0) 2020.05.17 [2020.Q1] Deep Learning Paper List (0) 2020.01.21 [PR#1] (Pruning) Learning both Weights and Connections for Efficient Neural Networks (NIPS 2015) (0) 2020.01.07