[PR#1] (Pruning) Learning both Weights and Connections for Efficient Neural Networks (NIPS 2015)
[LINK] : https://arxiv.org/abs/1506.02626
Learning both Weights and Connections for Efficient Neural Networks
Neural networks are both computationally intensive and memory intensive, making them difficult to deploy on embedded systems. Also, conventional networks fix the architecture before training starts; as a result, training cannot improve the architecture. To
arxiv.org
_____________________________________________________________________________________________________________________________________________________________
1. What is Pruning?

Pruning이란 최종 결과에 기여하지 않는 Network를 잘라내는(prune)하는 것이다. Accuracy Loss를 희생해서 Parameter 수와 Computation을 줄이는 기법이다. 이 논문에서 소개하는 Pruning 기법은 Iterative pruning이다. Figure2를 다시 설명하면 아래와 같다.
Step 1. Learning which connection is important
Step 2. Prune and Traing iterativly
2. How to Prune?

L2 Regularization을 사용하면서 iterative purning을 했을 때 Accuracy Loss 대비 Parameter를 효과적으로 줄일 수 있다. 주목할만한 점은 Pruning이 Accuracy를 크게 희생하지 않으면서 Parameter와 Computation을 효과적으로 줄인다는 것이다. 혼동하지 말아야 하는 점은 Pruning 시에는 L1 norm을 사용하는 것이 일반적이고, Prune 후에 retraining을 위한 iteration을 돌릴 때는 L2 regularization을 사용한다는 점이다.

AlexNet과 VGG-16의 경우, Prune되었을 때 Weight와 Computation이 (9x, 3x), (12x, 5x)만큼 줄었다. FC Layer가 Conv Layer보다 Pruning이 많이 되었고, 실제 CNN에서 FC Layer는 Conv Layer에 비해 Parameter와 Computation에 기여하는 정도가 지배적이므로 효과적인 Pruning을 위해 초점을 맞춰야하는 대상은 FC Layer라는 결론을 내릴 수 있다.

Figure 6를 보면 FC Layer가 Conv Layer에 비해 Pruning되는 정도가 큰 것을 알 수 있다. Conv Layer는 FC Layer에 비해 Pruning에 Sensitive하다. Conv1 Layer를 주목해보면, Image를 input으로 받는 Layer이므로 Chennal 수가 RGB 3개 밖에 없어 Redundancy가 다른 Layer에 비해 떨어진다. 따라서 Pruning Threshold가 낮다.
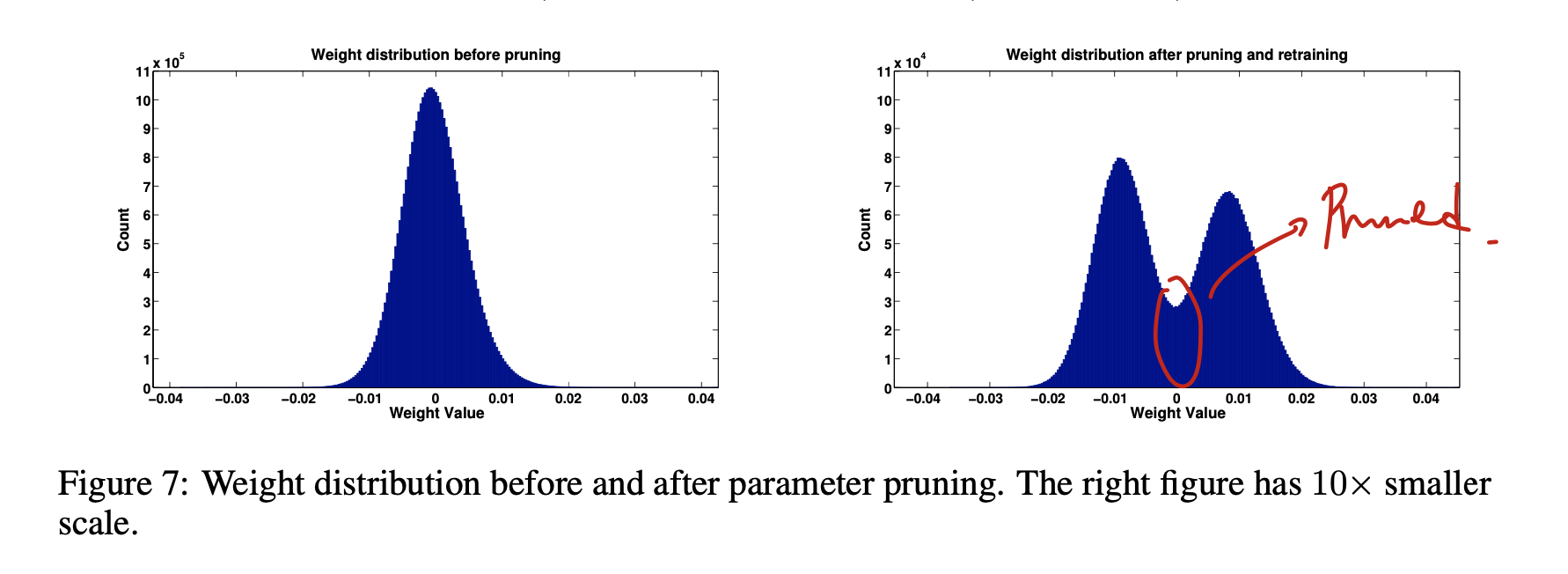
Prune 결과 Weight가 0에 가까운 unimportant한 node들이 제거된 것을 확인할 수 있다.
_______________________________________________________________________________________________________________________________________________________________
After pruning, the storage requirements of AlexNet and VGGNet are are small enough that all weights can be stored on chip, instead of off-chip DRAM which takes orders of magnitude more energy to access (Table 1). We are targeting our pruning method for fixed-function hardware specialized for sparse DNN, given the limitation of general purpose hardware on sparse computation.
_______________________________________________________________________________________________________________________________________________________________
결론 : Pruning을 이용하면 Storage 제한이 있는 Mobile기기에서 외부 메모리(DRAM)없이 on-chip만으로 Sparse DNN을 구현할 수 있다.
_______________________________________________________________________________________________________________________________________________________________
[Futher Question]
Q1. Pruning에 의해 Parameter가 줄었을 때, 이를 Compensate하기 위해 Training Dataset이 더 필요로 하지는 않는가?
Q2. Pruned Layer는 irregular하므로 Storage에서 Ovehead가 발생하는가?
[Related Works]
-
Vincent Vanhoucke, Andrew Senior, and Mark Z Mao. Improving the speed of neural networks on cpus. In Proc. Deep Learning and Unsupervised Feature Learning NIPS Workshop, 2011.
-
EmilyLDenton,WojciechZaremba,JoanBruna,YannLeCun,andRobFergus. Exploiting linear structure within convolutional networks for efficient evaluation. In NIPS, pages 1269–1277, 2014.
-
Yunchao Gong, Liu Liu, Ming Yang, and Lubomir Bourdev. Compressing deep convolutional networks using vector quantization. arXiv preprint arXiv:1412.6115, 2014.
- Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural network with pruning, trained quantization and huffman coding. arXiv preprint arXiv:1510.00149, 2015.
- NISP: Pruning Networks using Neuron Importance Score Propagation (Important Connection의 Score를 매기는 방법)