CS 분야 회사 면접 대비 - Quick NOTE
* NAVER, KAKAO 등 CS 관련 회사 면접 대비 자료입니다.
* 이미 관련 분야 지식이 있으나, Remind를 위한 목적으로 작성되었습니다.
* Keyword 별로 정리해두었습니다.
* 1 page에 모든 것을 끝낼 생각입니다.
* 미작성, 보강, 완료
[Log]
20/04/13 : First Commit
[목차]
1. 딥러닝
2. 컴퓨터 조직론
3. OS
4. DB
5. 컴파일러
6. 네트워크
7. 알고리즘
8. 자료구조
9. OOP
10. 예상 질문
[딥러닝]
- SGD, Saddle Point
- Activation Function(Relu, Leaky Relu. Why Relu?)
- Optimizer( ADAM, RMSProp, Adagrad, Momentum, ADADelta)
- Generalization
- Batch Normalization:
- inference 시에는 training 단계에서 썼던 batch들의 평균과 분산을 다시 평균내어 사용한다.
- CNN에서는 Channel별로 BN layer를 둔다. Conv Layer가 (N,W,H,C) 라면 C개의 beta, gamma가 존재한다.
- BN folding : BN을 Conv와 합치는 것 [CONV]-[BN]-[RELU]
- 아래 inference graph에서와 같은 수식으로 fold되는 것 (Google의 CVPR18 논문 발췌)

* 참고 링크 : https://shuuki4.wordpress.com/2016/01/13/batch-normalization-%EC%84%A4%EB%AA%85-%EB%B0%8F-%EA%B5%AC%ED%98%84/
- Weight Normalization
- Weight Initialization
- Backprop
- CNN
- VISION
- RNN, LSTM, GRU
- Transformer, BERT
- Pruning, Quantization
- Pytorch
- torch.no_grad()와 torch.eval() 차이 : no_grad는 grad update만 방지하는 것. eval()은 BN과 Dropout을 inference mode로 바꿔준다.
- TensorFlow Graph
[컴퓨터조직론]
- Register - L1/L2/L3 Cache (SRAM) - Memory (DRAM)
- Cache Index를 중간 비트로 사용해야 하는 이유 : Spatial Locality 때문이다.
[ACA] 캐시 메모리의 인덱스로 중간 비트를 사용하는 이유
캐시 메모리 공부를 할 때 Direct-mapped cache, Set-associative cache 를 배운다. 얘들을 잘 살펴보면 캐시 메모리의 인덱스로 중간 비트를 사용한다. 상위 비트를 사용할 수도 있을텐데, 중간 비트를 사용하는..
xxxxxxxxxxxxxxxxx.tistory.com
- Direct-Mapped Cache : Tag-Index-(Block)-Offset로 이루어짐. Index로 Cache를 조회하고 Tag가 일치하는지 확인
- n-way Set-Associative Cache : Direct Mapped Cache를 여러개로 붙인 것
- Fully Associative Cache : index 조회 없이 Tag를 모든 Cache entry에 대응시키는 것



[OS]
Ch2. Introduction to OS
- MMU
- 매우 초기 OS 당시부터 존재
- MMU(Memory Management Unit)에 의해 Base/Bound Register가 정해지고 이를 통해 Multi-Process들 간의 Memory Protection/Relocation이 가능해짐. (MMU는 H/W로 구현해야함. MMU 자신도 Process가 되면 자기 자신도 관리되어야 하므로)
- MMU는 OS의 Priviliged Instruction
- MMU에 의해 [CPU]-(Logical Address)->[MMU]-(Physical Address)->[Memory]
- I/O : Char(키보드, 마우스), Block(메모리), Network로 나뉨
- OS의 기능 : 리소스 중재, High-Level Interface, 유용한 Library를 제공함
Ch3. Review of Computer Hardware
- System Bus : Data Bus / Address Bus (Bus Arbiter에 의해 Bus master들의 요청을 중재)
- Bus Master : CPU, DMA Controller
- Bus Slave : I/O Controller, Memory Controller
- Interrupt-driven I/O
- Polling I/O (I/O가 끝날 때까지 CPU가 주기적으로 확인)
- Memory-mapped I/O (I/O Reg를 Memory 주소에 Mapping. 별도 inst 불필요)
- Port-mapped I/O (I/O Reg를 위한 Port 할당. I/O Bus 필요)
- DMA(Direct Memory Access)
- Cycle Stealing : CPU가 BUS를 안 쓸 때만 씀
- Block Transfer : CPU와 DMA가 대등
- Interrupt
- H/W Interrupt (Async)
- S/W Interrupt (Sync) ex. Exception, System Call
- Exception : ex. 0으로 나누는 상황
- System Call : User mode에서 하드웨어 자원(메모리 할당)을 받기 위해 Kernel Mode를 이용하는 것
- System Call 발생 예시

- 또 다른 예시
- User가 read()를 호출
- read()는 컴파일 되었을 때 mov $3, %eax (이 때 $3는 read syscall의 index)
- int 0x80이 불리면
- S/W Interrupt에 의해 Interrupt Dsecriptor Table의 0x80번 인덱스를 가진 SysCall이 호출된다.
- Syscall의 3번 index에 해당하는 read 서브루틴이 실행된다.
- Syscall vs Function call : Syscall은 mode change를 동반
- Interrupt Mechanism
- 실행 중이던 process를 중지
- Interrupt 유효성을 검사하고 승인 신호를 Interrupt를 보낸 기기에 보냄
- PIC(Programmable Interrupt Controller)에 의해 Interrupt 활성 flag를 켜고 끈다(Interrupt 진행 시 다른 Interrupt 방지)
- 실행 중이던 process의 Context는 저장(Kernel 영역의 PCB에 저장)
- H/W든 S/W든 Interrupt 처리는 Kernel Mode로 전환 후 시작(PSW를 1->0으로 변경)
- Interrupt Vector Table에서 IRQ(Interrupt Request) number를 조회해서 해당 ISR(Interrupt Service Routine, also called Interrupt Handler)의 주소를 가져옴
- Interrupt 처리는 최대한 빨리 이루어져야하므로 Vector Table은 fixed low memory(주소값이 낮은)에 존재
- 해당 ISR로 Jump한다.
- Interrupt 처리가 끝나면 커널 스택에서 다시 Process의 Context를 복구한다.
- Dual Mode Operation
- Mode bit에 의해 User/Kernel Mode를 구분하는 것.
- Kernel Mode는 Privileged Instruction을 수행할 수 있음
- 경우에 따라 mode가 더 많아지기도 함
Ch4. Processes and Threads
- Process : Program을 수행시키는 주체, 단위
- Execution Stream : 지금까지 수행한 Instrcution Sequance
- Context : Process의 상태
- Memory Context : Code/Data/Stack/Heap Segment
- Hardware Context : CPU, I/O Reg
- Kernel Context : page table, file table, process table
- Process Status Word(PSW) : (보통 64bit 안에 Interrupt Mask, Privilege States(Mode Bit), Condition Code, Instrcution Address 정보를 포함함)
- Context Swtiching : 멀티프로세스 환경에서 CPU가 어떤 하나의 프로세스를 실행하고 있는 상태에서 인터럽트 요청에 의해 다음 우선 순위의 프로세스가 실행되어야 할 때 기존의 프로세스의 상태를 저장하고 CPU가 다음 프로세스를 수행하도록 새로운 프로세스의 상태 또는 레지스터 값(Context)를 교체하는 작업
- Context Swtiching 시 CPU가 아무것도 하지 못하므로 잦은 Context Swtiching은 성능 저하를 일으킴
- PCB(Process Control Block)는 Context를 보관하는 것으로 주로 다음과 같은 정보들을 저장하게 된다.
- (1) Process State : 프로세스 상태
- (2) Program Counter : 다음에 실행할 명령어 Address
- (3) Register : 프로세스 레지스터 정보
- (4) Process number : 프로세스 번호
- Thread 의 경우 Process 내의 TCB(Task Control Block) 라는 내부 구조를 통해 관리

- Process는 Shared Memory(user memory) 또는 Message Queue(kernel memory) 방식을 통해 통신
- Shared Memory는 커널에 권한을 요하지 않아 더 빠르다. 초기 셋팅에서만 Mem 할당을 위해 커널 모드를 요한다.
- Process가 자신의 User 메모리에 접근 할 때는 Kernel mode를 요하지 않는다.
- Mutlicore환경에서는 Messeage Queue가 더 빠르다. (Cache Coherence 때문에)

- Process Creation
- UNIX에서는 딱 한번만 process 0를 만든다. 이후 fork() 해서 자식 process를 생성함.
- child에서 exec()후에 exit() 후에는 다른 child를 기다리는 zombie state가 된다.

- Multi-Threading : 1) concurrncy, 2) Resource Sharing
- Process와 Thread 차이
- Process 와 Thread 를 처리하는 ContextSwitching 은 조금 다른데, PCB는 OS에 의해 스케줄링되는 Process Control Block이고, Thread 의 경우 Process 내의 TCB(Task Control Block) 라는 내부 구조를 통해 관리된다.
- Thread는 프로세스 내에서 각각 Stack만 따로 할당받고 Code, Data, Heap 영역은 공유한다.
- Dispatcher Thread : Thread 스케쥴러
- Worker Thread : 일하는 Thread
- User-Level Thread
- OS(Kernel)와 무관. Thread Library만 있으면 된다. User Process의 일. User Process마다 정책이 다를 것.
- 하나의 Thread가 Blocking/Syscall을 요청할 경우 모든 Thread가 정지. Kernel 모드에 진입
- 장점
- thread 간 switching에서 interrupt 불필요
- 어떤 OS에서든 돌아감 (Library만 필요)
- 단점
- Thread하나가 Block당하면 전체 Thread가 Block
- 장점
- Kernel-Level Thread
- Syscall 등 Kernel func이 thread화됨.
- Kernel thread와 User thread가 1:1 mapping
- Thread 하나가 kernel mode에 진입해도 다른 Thread는 돌아갈 수 있음
- 장점
- process 단위가 아니라 thread 단위로 여러 CPU가 수행할 수 있음 (Concurrency가 높음 )
- Thread 단위로 Blocking이 일어남
- Kernel Routine도 Multi-Threading이 가능
- 단점
- Thread Switching에 kernel이 개입해서 느려짐(kernal mode로 진입해야 하므로 context swtiching) (10배 정도 느려진다고 한다)
- Kernel이 관리해야할 Thread가 늘어나 Scheduling이 복잡해진다
- 장점
- Pthread: 유저, 커널레벨 스레드 모두 구현 가능한 라이브러리, posix standard의 thread extension
- Windows thread: 커널레벨 스레드 라이브러리
- Java thread: 자바는 운체위에 실행되는데, 실제로 pthread나 windows thread를 이용해서 구현됨
* 참고 자료
- https://jeong-pro.tistory.com/93 [기본기를 쌓는 정아마추어 코딩블로그]
- https://jins-dev.tistory.com/entry/컨텍스트-스위치Context-Switching-에-대한-정리 [Jins' Dev Inside]
* Process 간 통신 IPC(Inter Process Communication)에 대한 설명 : https://xxxxxxxxxxxxxxxxx.tistory.com/entry/OS-Inter-Process-Communication-IPC
Ch5. CPU Scheduling
- FIFO
- SJF(Shortest Job First) : Starvation 문제
- RR(Round Robin) : Time Slice를 주고 끝나면 Ready Queue의 맨 뒤로 감
- Multi Level Feedback Queue : 우선순위가 여러개
Ch6. Synchronization
- MUTEX(Mutual Exclusive) : 멀티프로세서/쓰레드 환경에서 Critical Section에 동시에 접근 못하도록 프로세스가 자원을 쓰는 동안 걸어 놓는 LOCK(Boolean)
- Semaphore : MUTEX보다 더 많은 LOCK을 지원하고, wait(), signal()을 지원(Binary/Count Semaphore)
- 이전에는 자기가 자원을 쓰는동안 다른 프로세스가 침범하지 못하도록 interrupt disable을 썼음
- Monitor : Semaphore보다 High-level에서 쓰는 ADT
- x.wait() : x 자원을 누군가 쓰고 있으니 기다려라
- x.signal() : x 자원을 다 쓰고, 기다리고 있던 하나의 프로세스를 깨운다.
- x.broadcast() : x 자원을 다 쓰고, 기다리고 있던 모든 프로세스를 깨워 경쟁시킨다.
- Monitor는 Semaphore로 구현 가능하다.
- Race Condition : 여러 주체들이 하나의 공유자원을 가지고 경쟁하는 것
- DATA Segment
- Text(Code)
- Stack : Local VAR, Function call
- Data : 초기화 된 Global/Static VAR
- BSS : 초기화 되지 않은 Global/Static VAR
- Heap : Dynamic Allocation
- Deadlock : Process들이 Resource를 일부 가지고 있으면서 요구하는 상황. 남는 Resource 여유가 없을 때 무한히 wait하게 된다.
- Deadlock이 일어날 수 있는 조건
- Mutual Exclusion
- No Preemption
- Hold and Wait
- Circular Wait
- Banker's Algorithm : 간단히 말해 시뮬레이션을 돌려서 Deadlock이 발생할 수 있는지 확인하는 알고리즘
- Deadlock이 일어날 수 있는 조건
- Lock을 잡지 못할 경우에 wait하는 방법이 있고 sleep하는 방법이 있는데 각각의 장단점이 무엇인가?
- sleep(1000) : 1000ms동안 기다렸다가 스케쥴러에 의해 깨어남 ( Process Schedular의 비동기적 방법에 의해 깨어난다)
- wait(1000) : 1000ms동안 기다리다가 Lock이 해제되면 notify를 받음 ( Synchronous한 Thread 사이에서 잠들고 깨어난다)
Ch 7. Segmentation and Paging
- Address Translation : Logical Addr -> Physical Addr (by MMU)
- Segmentation : Process마다 RW 권한에 따라 Base/Bound를 통해 Segment를 나눠 Logical Address를 Physical Address에 Mapping (Code, Data, Stack, Heap)
- PCB에서 Base/Bound 정보를 가진 Segment Table을 보관
- External Fragmentation을 발생시킴. (Physical Memory 상에서 Seg들이 연속적으로 배치되다보니 Seg들 사이의 메모리가 낭비된다. Fragmentation이 생긴다.)
- Paging
- External Fragmentation을 피하자
- Memory Allocation/Swap을 쉽게 하자
- 장점 :
- 쉬운 Allocation (Free List를 이용하면 편하다).
- No External Fragmentation
- 단점 :
- Page Table이 너무 크고 Main Memory에 존재한다. MMU는 Page Table의 Base주소만 가지고 있어, page를 하나 참조하기 위한 메모리 OP overhead가 발생한다.
- Internal Fragmentation : 필요한 정보를 가져오려면 Page 단위를 전부 가져와야 한다. 그렇다고 Page를 작게 만들면 Page Table의 크기가 늘어난다.
- Paged Segmentation
- Seg table -> Page table을 찾는다
- Page를 쓰니까 External Fragmentation이 사라졌다.
- Page 크기가 작아져서 Internal Fragmentation이 줄어들었다.
- 여전히 Page Table이 크다
- Multi-Level Page Table
- VAX에서는 Seg Table 이후 두 단계로 Page Table을 구성해 Page Table 크기를 줄였다.
- User Page Table(Logical Addr, Scatterd)
- System Page Table(Physical Addr, Contiguous)
- 하지만 Address Translation이 많아질수록 overhead가 생김
- TLB의 등장 : Translation Look-aside Buffer
- Page Table의 Cache라고 생각하면 된다.
- Logical Page Number -> Physical Page Number
Ch8. Demand Paging
- Page Fault
- Page Replacement Policy
- RAndom
- FIFO
- OPT : 불가능
- LRU(Least Recently Used)
- Thrashing : Page Fault가 발생해, Page를 교체하는 과정에서 Page Fault 연쇄적으로 발생해 System이 오랬동안 멈추는 것
- Working Set : 어느 시점에 특정 프로세스가 Access하는 Page 집합
- Resident Set : 현재 physical memory에 있는 page set
- Balance Set : Working Set이 mem에 모두 있는 process 집합
- Temporal Locality : 참조했던 메모리의 같은 주소의 재방문 확률이 높다
- Spatial Locality : 참조했던 메모리의 근처 주소의 재방문 확률이 높다.
Ch9. GNU Linker
- Compiler : source file -> object file
- Linker : object file들 -> exe file
- Loader : exe file을 읽어서 Memory에 Load하는 것
Ch10. File System
- RAID : Redundant Array of Independent Disk
- 대용량의 단일 볼륨을 사용하는 효과
- 병렬화로 인한 성능 향상
- 데이터 복제로 인한 안정성
- RAID 설명 잘해놓은 링크 : https://harryp.tistory.com/806
- RAID 0 : 디스크에 균등하게 분할해서 씀. (용량 활용 최대)
- RAID 1 : 디스크에 균등하게 복제해서 씀. (안정성 최대)
- RAID 5 : RAID 0에서 패리티 1개를 균등하게 저장함
- RAID 6 : RAID 0에서 패리티 2개를 균등하게 저장함
[스토리지] RAID 정리 1. RAID 기본 설명 및 RAID Level (레이드 레벨)
안녕하세요. 본격적으로 RAID에 대한 얘기를 해보겠습니다. 1. RAID 란? RAID는 Redundant Array of Independent Disk (독립된 디스크의 복수 배열) 혹은 Redundant Array of Inexpensive Disk (저렴한 디스크의..
harryp.tistory.com
[DB]
- Abstraction Level
- Physical Level : File
- Logical Level : Relation, Schema(Logical Structure)
- View Level : Application
- Relational Model : Table로 표현(Attribute, Tuple)
- E-R Model (Entity-Relation)
- JSON (JavaScript Object Notation) : Human Readable한 DB model
- NoSQL(Not Only SQL)
- 최근 많이 사용
- Relational DBMS 특성 외에 부가적 특성을 지원
- 비정형 데이터 처리에 적합
- Relational DBMS처럼 ACID(Atomic, Consistency, Integrity, Duarabity)를 제공하지는 않음
- DBA : DB Admin (DB의 모든 수정 권한을 가짐)
- Key
- super key : 하나의 tuple을 뽑아 낼 수 있는 Attritbute 집합
- candidate key : super key 중 가장 작은 것들
- primary key : candidate key 중 선택된 하나
- foreign key : 다른 table에 등장하는 attribute(참조할 수 있도록 함
- Relational Query Language
- Select : tuple 추출
- Project : Attribute 추출
- Cartesian Project : 두 table의 모든 조합을 출력
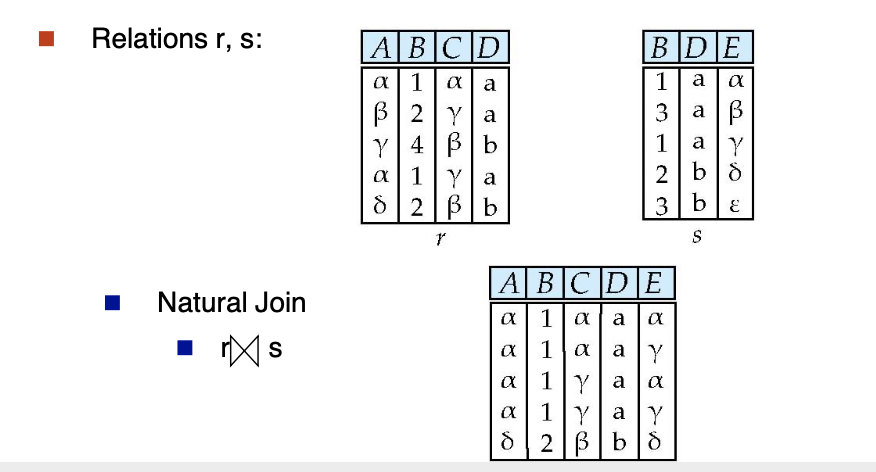
- Join : 같은 Attribute가 있으면 같은것끼리만 조합
- Union Set
- Minus Set

- select attribute from table where condition in ( select attribute from table where condition )
- insert into / delete from / update
- VIEW : DB의 모든 데이터가 아닌 일부 데이터만 사용자에게 보여줌. 실제 DATA는 아님. (Virtual Relation)
- Materialized View : View의 Update가 잦으면 Update할 때마다 View를 새로 만들어야 하므로 Physical table로 만들어 둔 것
- Transaction
- Commit
- Rollback
- Dynamic SQL : SQL로 DBMS와 Communication을 위한 API
- JDBC : Java API
- ODBC : C/C++ API
- E-R Model
- Entity ~ Attribute
- Weak Entity : Primary Key를 가지고 있지 않음. Strong Entity의 primary key에 의존
- Entity 사이의 관계
- 1:1
- 1:n
- n:m - 1:n과 1:m이 엮여있는 관계 ex. 좋아요 (유저는 여러 글을 좋아요 할 수 있고, 좋아요한 글은 여러 유저를 가질 수 있음)
- Lossless Join Decomposition
- Normalization Form
- 1NF - 2NF - 3NF - BCNF - 4NF - 5NF
- Index : DB Search를 더 빠르게 해줌
- Primary Index : 첫 번째
- Secondary Indice : 두 번째 index. 늘어날 수록 maintainance cost 증가 (insert, delete, update로 인한)
- B+ Tree : B-Tree보다 Search가 빠름. fanout(한 노드의 자식 노드 수)을 늘림. 구현은 복잡함
- B+ Tree File : Index가 Pointer가 아닌 Data자체가 되게 하자.
- 데이터 무결성을 위해 DBMS가 지켜야 할 원칙
- ACID(Atomicity, Consistency, Integrity, Duarabity)
- Atomicity : transaction은 Atomic하게 전부 반영되거나 반영되지 않아야 한다. (부분 반영x)
- Consistency : transaction은 DB의 일관성을 유지해야한다.
- Isolation : transaction은 독립적으로 동작해야 한다.
- Durability : transaction이 Disk에 잘 반영되어야 한다.
- Exclusive Lock : 쓰기 잠금. (X Lock 이후 같은 자원에 X/S Lock을 걸 수 없다.)
- Shared Lock : 읽기 잠금 (S Lock 이후 같은 자원에 S Lock만 걸 수 있다.)
1. NULL 무결성 : 릴레이션의 특정속성 값이 Null이 될 수 없도록 하는 규정
2. 고유 무결성 : 릴레이션의 특정 속성에 대해서 각 튜플이 갖는 값들이 서로 달라야 한다는 규정
3. 참조 무결성 : 외래키 값은 Null이거나 참조 릴레이션의 기본키 값과 동일해야 한다는 규정 즉 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다는 규정
4. 도메인 무결성 : 특정 속성의 값이, 그 속성이 정의된 도메인에 속한 값이어야 한다는 규정
5. 키 무결성 : 하나의 테이블에는 적어도 하나의 키가 존재해야 한다는 규정
[컴파일러]
- Front-end : Analysis (Lexical, Syntax, Semantic)
- Back-end : Synthesis (Code Gen, Optimization)
- Lexical Analysis : token을 찾아내는 작업
- Syntax Analysis : 문법을 번역하는 과정
- Semantic Analysis : 문법이 아닌 것을 번역
- Compiler : 언어를 번역해서 다른 언어, IR, exe를 만들어내는 것 (in Static Time)
- Interpreter :
- VM을 이용해 source를 바로 execute하는 것 (Debug, Portability, faster Develop) ex. JS, Python (in Dynamic Time)
- VM 즉, SW 안에서 돌아가야 하므로 명령어 번역이 길다.
- Hybrid Compiler : ex. JAVA. IR(bytecode)로 Compile 후 VM을 통해 interprete되는 것.
- Compiler의 목적 : Correctness, Efficient Code Generation
- Compiler Structure


- VM :
- DaD : Naive Decode-and-Dispatch Interpretation : 단순히 opcode를 dispatch
- Threaded Interpretation
- JIT : IR to Machine Code를 run time에 하는 것. 코드가 hot할 수록(자주 사용될 수록) Optimization, Translation level을 높임. Profiling based OPT (과거 Code 사용빈도를 확인해서 OPT에 참고)
- Garbage Collection(GC) : JVM에서 명시적이지 않게 메모리를 Free하는 과정
- Stop-the-world : GC thread 실행을 위해 JAVA의 모든 thread를 중단하는 것. 이 명령어를 자주 발생시키지 않도록 하는게 opt
- Weak generational hypothesis
- 1) 대부분 객체는 금방 접근 불가능 상태가 된다.
- 2) 오래된 객체에서 젊은 객체로의 참조는 아주 적게 존재한다.
- Young Region
- 새로 생성된 객체는 먼저 Young 영역에 존재. 오래 되면 OLD 영역으로 이전 (Minor GC)
- Eden -> 2개의 Survivor -> OLD
- Serial GC
- Old Region
- Serial/Parallel/Concurrent Mark & Sweep GC
* 참고 자료
> 19-2 컴파일러의 기초 - 문수묵 교수님
> https://d2.naver.com/helloworld/1329
> https://jungwoon.github.io/java,%20gc/2019/07/27/Garbage-Collection/
[Algorithm]
* pseudo code 작성
* 시간복잡도 외우기
- Sorting(Bubble, Insert, Merge, Quick)
- Graph(BFS, DFS, Dijkstra, Bellman-ford, Floyd-Wassal)
- Suffix Trie, Tree, Array 알고리즘 외우기
- P-NP
[Data Structure]
- Hash :
- 기존 Tree에 비해 Find, Insert, Delete를 O(1)에 할 수 있다. (높은 확률로)
- ex. Symbol Table (in Compiler), Page Mapping (in OS), Dictionary (Python, JAVA)
- Key-Bucket Pair로 존재. Bucket에는 Value들이 있음
- Hash Function을 Collision이 없게 잘 디자인 해야한다.
- String은 Char단위로 shift해서 더하고 소수로 나눈 나머지로 Hash Function에 넣음 (일반적)
- Open Hash : Collision 시 Bucket에 List형태로 이어가는 것
- Closed Hash : Collision 시 다음 Hash Function을 이용해 Collision을 피하는 것. (Linear/Quadratic Probing)
- Delete : Closed Hash에서는 Delete 후 Delete되었다는 표식을 남겨야 함. 그래야 나중에 탐색을 할 수 있음.
- Linear Probing : Collision 시 다음 Bucket을 Linear하게 탐색함. (pros : O(n) time안에 빈 곳을 찾아냄 / cons : Primary Clustering(차 있는 bucket이 연속적으로 모이는 경향이 있음)
- Quadratic Probing : [ h(key) + i^2 ] % B로 찾는 것 (Secondary Clustering : 초기 Hash function이 겹치면 결국 Collision이 연속적으로 발생함
- Double Hashing : [ h1(key) + i * h2(key) ] % B ( h1, h2는 서로소인 소수로 이루어져야 함 )

*참고 링크 : HASH - https://ratsgo.github.io/data%20structure&algorithm/2017/10/25/hash/
- Balance Tree : BST(Binary Search Tree)에서 Avg Case O(logn)이지만 Worst Case O(n)인 점을 해결하기 위해 적절한 Tree Height를 유지 하기 위한 Tree
- AVL Tree : 어떤 노드든지 좌우 높이 차이가 +-1이 되도록 유지
- Red-Black Tree : 어떤 노드든지 leaf node까지 black 수가 일정하게 유지
- B-Tree : DB 참고
[OOP]
- OOP(Object-Oriented Programming)
- 코드의 재사용성과 중복제거가 가장 큰 목적
- 추상화(Abstraction)
- 목적과 관련이 없는 부분을 제외해서 단순화
- 객체의 공통된 속성들 중 필요한 부분을 포착해서 클래스로 정의하는 설계 기법
- 캡슐화(Encapsulation)
- Data와 Method를 묶는다.
- 외부에 노출할 필요가 없는 정보들은 은닉 (정보은닉) Infromation Hiding
- 상속(Inheritance)
- 상속 관계에 있는 두 클래스에 대해, 부모 클래스가 자손 클래스에게 속성을 물려주는 것
- 코드의 재사용이 목적
- 다형성(Polymorphism)
- 같은 형태이지만 다른 기능을 하는 것
- 오버라이딩(Overriding)
- Overriding : Class 사이의 다형성 (자식 Class가 부모 Class Method를 재정의하는 것)
- Overloading : Method 사이의 다형성 (같은 Class 내에서 Method를 param을 다르게 여러 형태로 정의하는 것)
*외우기 어렵다면 o가 들어가있으면 overlOading - methOd
- SOLID 원칙

[자소서 기반 질문]
[일반적인 면접 질문]
Sync : 요청에 대한 결과가 일찍 나와도 Syscall등을 기다리고 가져온다.
Async : 요청에 대해 결과가 나오면 바로 가져다 준다. (요청을 보낸 주체와 관계없이)
협업 시 느낀 점
가장 어려웠던 개발
나의 장점
- public : 공개변수
- private : class 내에서만 쓸 수 있는 변수
- protected : 상속 관계에서 자식관계의 class에서만 접근 가능
- default : 같은 package 내에서 접근 가능
20. 당신의 꿈은 무엇인가요? 정말 솔직한 자신의 꿈을 말해주세요.
21. 이전 프로젝트에서 어떤 갈등이 있었고, 그 문제를 어떻게 해결했나요? 구체적인 사례를 들어 설명해 주세요.
22. 쿼리가 들어올 때, 어떻게 해야 효과적으로 저장할 수 있나요?
23. 이 직무를 위해 당신이 정말 이것만은 열심히 했다고 생각하는 것이 있나요? 무엇인가요?
24. 이전 직장에서 업무로 어떤 평가를 받았나요?
25. 당신의 성장 과정과 특정 기업 사이에서 연관된 부분을 발견하고, 해당 기업을 소개해보세요.
26. 기획으로 내려온 내용이 마음에 들지 않는다면, 개발자 입장에서 당신은 이를 어떻게 처리할 것인가요?
27. 지금까지 당신은 성공적인 사례만을 들어 본인을 소개했는데, 당신이 실패한 사례에 관해 얘기해 주세요. 그 경험으로 당신은 무엇을 배웠나요?
28. 자주 보는 네이버 웹툰은 무엇인가요?
29. 최근에 읽은 책은 무엇인가요?
30. 네이버 서비스 중 가장 개선하고 싶은 것은 무엇인가요?
31. 지구의 질량을 더하기만 써서 계산해 보세요.
32. ‘C언어’의 프로세스 공간에 관해 설명해 보세요.
33. 1부터 100까지 더하는 프로그램을 칠판에 작성해보세요.
34. 모바일 환경이 네이버 서비스에 어떤 영향을 미칠 것으로 예상하나요?
35. 회사가 어려우면 이직할 마음이 있나요? 이전 회사에서도 그러한 이유로 네이버에 지원하신 것 아닌가요?
36. 갑자기 준비한 PT 자료가 날아갔다거나, 데이터가 날아가는 등 위기 상황이 발생하면 어떻게 대처하실 건가요?
37. OSI 7계층이 무엇인지 설명해 보세요.
38. 소팅 알고리즘을 슈도 코드로 구현하되, 변수를 사용하지 않고 해보세요.
39. 가장 어려웠던 개발 경험은 무엇인가요?
40. 스택과 링크드리스트와 리스트의 차이점을 설명해 보세요.
41. 64비트와 32비트의 차이점은 무엇인가요?
1. 테스트 코드 관련 질문
2. 프로젝트 설계 내용
3. 프로세스와 스레드
4. 프라이어리티 큐의 구조 설명 X
5. 테스트 코드 관련 질문
6. SQL 인젝션 방어 코드 X
7. 스프링 MVC란
8. 디스패처 서블릿이란? X
9. BO와 DAO란?
10. 알고있는 정렬 알고리즘과 그중에 좋아하는 정렬알고리즘 -> 퀵소트 머지소트 힙소트 설명
11. 스택과 큐 설명
12. 톰캣은 멀티 프로세스인가 멀티 스레드인가
13. 아파치는 멀티 프로세스인가 멀티 스레드인가
14. 오버라이딩, 오버로딩
출처: https://www.reimaginer.me/entry/N사-신입-면접-경험 [Reimaginer]